
Small Language Models vs Large Language Models in Generative AI

In the ever-evolving landscape of technology, generative artificial intelligence (GenAI) is seen as a game changer for enterprises. Generative AI for business is changing enterprise operations, from streamlining processes to boosting productivity and transforming everyday workflows. According to a McKinsey Global Survey, 65% of respondents reported that their organizations are regularly using GenAI, nearly double the percentage from the previous survey conducted just 10 months ago. One significant aspect of this adoption wave is the utilization of large language models (LLMs), such as ChatGPT, Gemini and Llama, for content generation. These AI language models generate human-like responses to natural language requests, eliminating the need for explicit code.

Enterprises have understood the importance of GenAI and have started with their AI strategy grounded in the usefulness for their employees – to improve productivity and reduce digital debt – or to build applications/services around it or with it. However, as enterprises embrace these technologies, there are some major hindrances to their mass or easy adoption, just like any other app on their edge devices (mobile phones, laptops and smartwatches). Among these challenges, the size and resource intensity of large language models (LLMs) present significant obstacles, prompting a closer examination of small language models (SLMs) as a viable alternative.
Develop an AI Strategy and Roadmap for Your Business
Are you ready to join the AI revolution? Early and effective AI adoption is crucial for maintaining a competitive edge.
Comparing Small Language Models vs Large Language Models
These challenges primarily stem from the massive program size, resource-intensive (for both computing and storage) nature and data safety and security. Even if enterprises keep these deployment issues aside, they need the models to be subject matter experts rather than general experts. LLMs have limitations in this area due to their broad knowledge but shallow expertise. Their domain-specific knowledge and performance are diluted. Another major worry for enterprises is exposing sensitive data to these external LLMs, which poses security, compliance and proprietary risks around data leakage or misuse. These limitations motivate organizations to find models that are domain-specific, have the enterprises “context” and have solutions to the deployment challenges as well. This is why a new paradigm in language models has come into the picture.
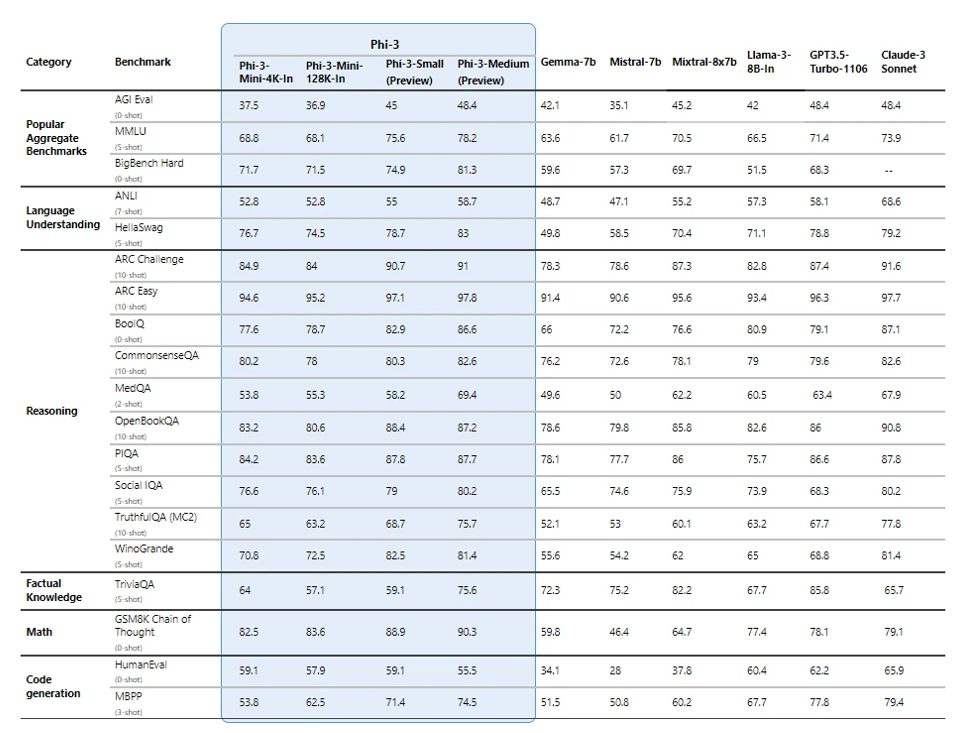
Enter the small language models (SLMs), which are like the Bruce Lee of language models: small but mighty! Just like its name, SLMs are small versions of their large counterparts. Small language models are generally models which have a million to a few billion parameters. These models are trained on a high quality of data and can include some level of architectural changes made for them to perform better. Examples are Phi-3, Chinchilla and Alpaca. These models are incredibly good when they are used in some specific use cases where they even outperform models that are fifteen times (15x) bigger than (LLMs). The image attached shows how Phi-3 and its variants perform in specific use case when compared to other models (LLMs). These SLMs perform better than (some) LLMs when they are trained with specific, high-quality datasets which is visible in the comparison below.
These small models are trained using quality datasets and can be achieved using some other techniques like:
- Knowledge Distillation: Knowledge distillation, also referred to as teacher-student learning, involves training a smaller model to replicate the learning or behavior of a larger language model (LLM) or an ensemble of models. One example of that was DistilBERT, which was a distilled version of Google’s BERT AI model. These models were learning from their teacher model’s predictions, with the aim of reproducing their performance while being lightweight. But, as the distilled language models try to mimic the performance of the larger models, they may not match the accuracy of the language models, even when those were lightweight.
- Pruning and Quantization: Involves removing less useful parts of neural network by means trimming unnecessary weights or connections. By doing this, we reduce the size of the model and computational requirements. Quantization reduces the precision of model weights and activations, which in turn decreases the model’s size. This reduction in precision lowers memory footprints and accelerates computations, making quantization particularly valuable for on-device or edge deployments.
- Improving Architecture: Even though the two techniques above may produce results, researchers are continuously looking at ways where the underlying algorithms improved to achieve the size and computational benefits while not compromising on its performance.
Advantages of SLMs
In the ongoing debate of Small Language Models vs Large Language Models, SLMs offer distinct advantages that make them particularly appealing for enterprises looking for effective and efficient AI solutions. Here are some of the key benefits of using SLMs vs LLMs:
- Better Performance and Accuracy: These models, when trained with quality data, have shown superior and dramatic gains over LLMs. If we augment these locally run small models with internet access, Retrieval augmented Generation (RAG) and self-training, it further boosts the accuracy and performance of these models.
- Confidentiality: One of the major worries of any enterprise is exposing their sensitive data to LLMs in the cloud. While cloud and model providers assure the safety and security of enterprise data, in situations where data privacy or security is crucial, these SLMs, which can operate locally with or without internet access, help prevent data misuse and leakage.
- Cost Effectiveness: LLMs are huge and can present significant costs when you need to finetune them based on your domain or use case. If it is used on the cloud, then the query pricing on its usage could be hefty in the long term. SLMs are small and cost less in both compute and storage which will eventually trickle down as lower costs for enterprises to either train on the technology or use them over the cloud.
- Running Locally: One major advantage of edge devices (hardware that controls data flow at the boundary between two networks) that could allow for mass adoption of AI, particularly SLM, will be their smaller sizes. Since an LLM cannot be installed and run locally, an SLM will make more sense if we see the use of AI models like apps we are already seeing on personal devices. Watch the Apple WWDC 2024 (Apple Intelligence) to see what this may look like.
Navigating the Limitations of AI Language Models
When considering SLM vs LLM, it’s crucial to evaluate the specific needs and constraints of the application. Even though it may look like a silver bullet, we need to take these AI language models with a grain of salt. These technologies may not be the best solution for every use case. On factual knowledge benchmarks, these models might not perform as well independently due to their smaller model size retaining fewer facts. This issue could potentially be addressed by implementing RAG. However, everything depends on the use case, and some can result in either LLMs, SLMs or a combination of both as the best fit. Therefore, enterprises should determine the use of these models based on their specific use cases and develop a strategy to explore and implement these generative AI for business options effectively.
Figure 1 : Comparison of SLM with other models. Courtesy of https://encord.com/blog/microsoft-phi-3-small-language-model/
Contact Us
Whether you’re just starting your AI journey or looking to enhance your existing capabilities, Withum will meet you where you are. Contact our AI Services Team today to see what’s possible.